
Most people think you learn AI by watching YouTube tutorials. Inside the industry, that’s not how the real experts learn. Engineers at places like OpenAI, DeepMind, Anthropic, and Meta learn by reading research papers. Not all of them cover-to-cover, not all at once, and definitely not like a novel. But they read papers because that is where new ideas and breakthroughs appear first. I learned this back in 2017, when I was an engineering manager at Meta. A paper called “Attention Is All You Need” dropped, and it completely changed the future of AI. In this post, I’ll walk you through the right way to read research papers, five papers that give you a strong foundation in AI, and where to find more papers without getting overwhelmed.
Exaltitude newsletter is packed with advice for navigating your engineering career journey successfully. Sign up to stay tuned!
Let’s start with the biggest misunderstanding.
Most beginners open a paper and start reading line by line from page one. That never works.
Research papers are not written like blog posts. They are dense. They assume you know the background. They are not written to teach you step-by-step.
So instead of grinding through every word, use the five methods below. These are the same habits used by researchers, engineers, and grad students who read papers every week.
Andrew Ng, one of the most well-known educators in AI, says:
That is great advice, but it also sets a very high bar for beginners.
If you're just starting out, and feeling overwhelmed, start with five papers.
That’s enough to understand:
When you finish those five, stop and reflect:
Short cycles keep you motivated. Long cycles burn you out.
Most people search randomly and jump into papers that are way too advanced. Don’t do that.
Pick a topic first. Something specific:
Then make a list of five papers.
If your goal is foundations, your first paper should be Attention Is All You Need, because it introduced the Transformer architecture that powers every modern LLM today.
I’ll walk you through the next four papers soon, but let’s finish the reading strategy first.
Once you have your list, resist the urge to dive in.
Spend about 10 percent of your time skimming:
Your only goal at this stage is to decide if the paper is worth reading deeply. If it’s not the right fit, move on. No guilt. No pressure.
Research is about finding the right ideas, not forcing yourself to read every paper ever written.
If a paper makes it past your quick skim, don’t start reading from the top.
The best reading order is:
This gives you the “why,” the “what,” and the “so what” before the “how.”
It is also totally normal to skip sections that don’t make sense yet. Even experts skip technical proofs or math until they need them.
Reading papers is a cycle, not a straight line.
No one becomes good at reading research papers after one week. It takes time.
The more you read:

Reading papers is a long-term habit, not a short sprint.
Now, let’s go through the five papers that will give you a strong foundation.
This paper introduced the Transformer, the architecture behind GPT-4, Claude, Gemini, Llama, and almost every modern language model.
Before Transformers, models used RNNs and LSTMs that processed text one word at a time. They struggled with long sentences and took forever to train.
The Transformer replaced that entire design with self-attention, which lets a model look at any word and instantly understand how it relates to all other words.
This single idea made long context, faster training, and higher quality models possible.
If you want to understand modern AI, start here.

This is the GPT-3 paper. It showed something shocking: scale unlocks new abilities.
When a model becomes huge (GPT-3 had 175 billion parameters), it gains emergent skills like:
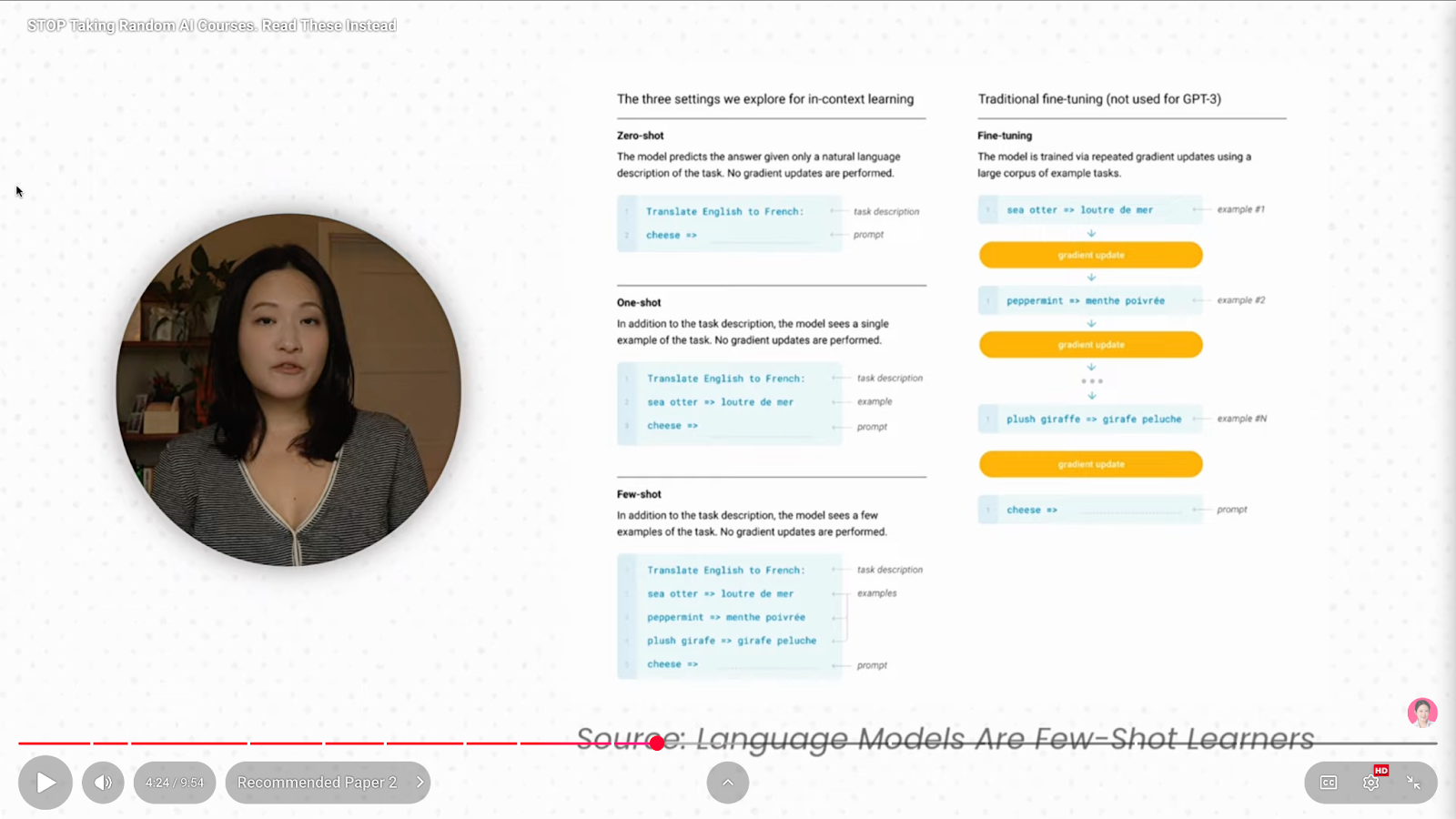
All without fine-tuning.
You could just give it a prompt with a few examples, and the model figured out the rest.
This shifted the entire field from:
“How do we train models?”
to
“How do we prompt them?”
That is why prompt engineering suddenly became a real skill. How you talk to the model matters more than how it was originally trained.
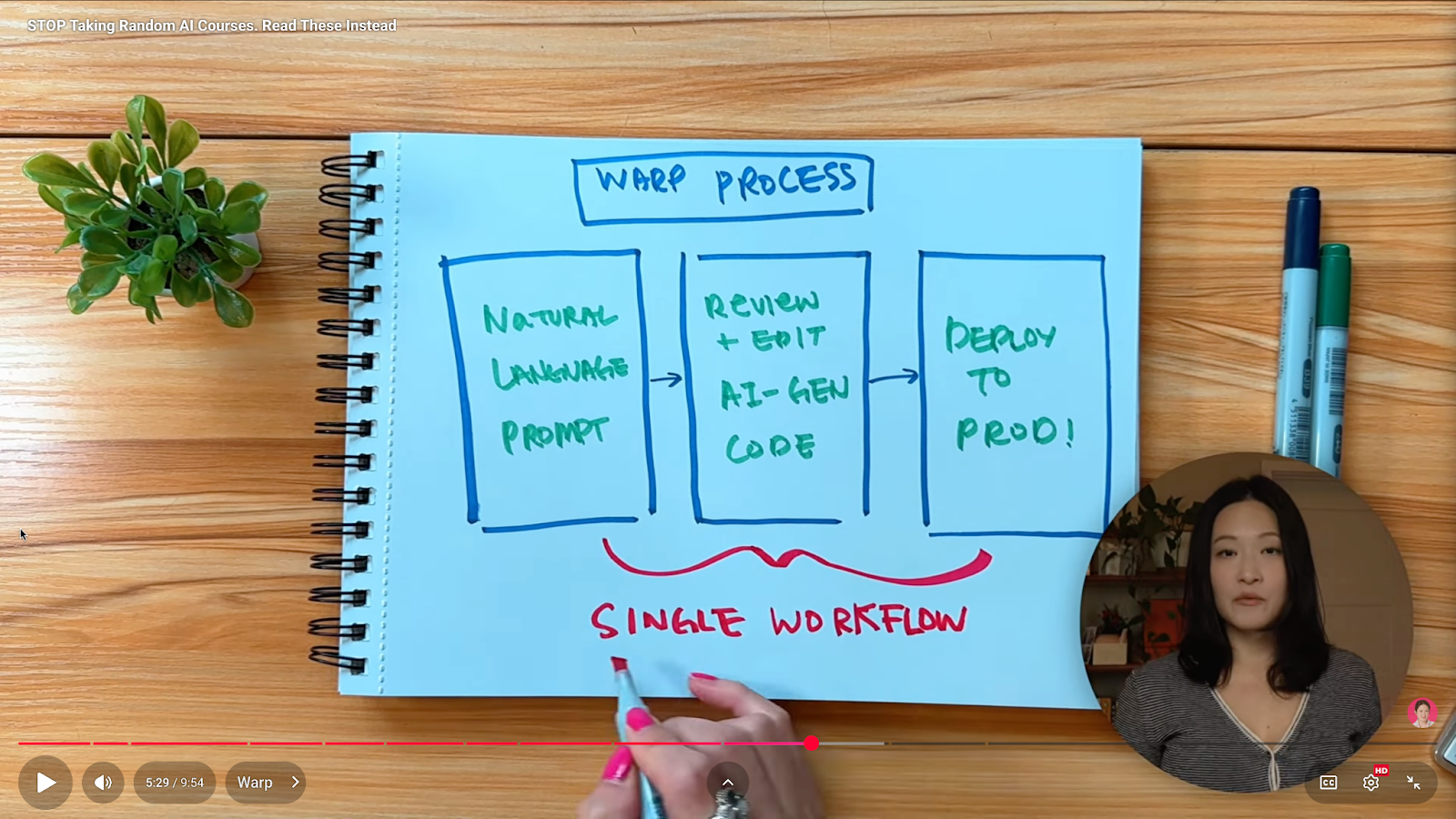
If you’ve been prompting more than coding lately, check out Warp.
Warp is a new kind of coding environment where:
All in one workflow.
It handles multiple long-running agents, reduces context switching, and is already used by more than 700,000 engineers and product teams, including 56 percent of Fortune 500 engineering organizations.
Warp is free to use. Try Warp for free today ➞ https://go.warp.dev/jeanytagents
This paper discussed the need for large language models that need massive amounts of training data. But high-quality real-world data is limited, copyrighted, or too expensive.
That’s where synthetic data comes in, data created by models to train other models.
DeepMind’s research highlights three key lessons:
1. Synthetic data is necessary but not enough
It must be mixed with real-world data for the best results.
2. Pure synthetic training leads to model collapse
If a model trains only on data created by other models, quality drops over time.
3. Verification and novelty matter
You need strong filters to ensure accuracy.
This paper is important because synthetic data is becoming a core part of how new AI models are trained.
If you’ve ever heard of RAG, this is the paper you should read.
RAG fixes three big problems:
RAG gets fresh, relevant information from external databases before the model responds.
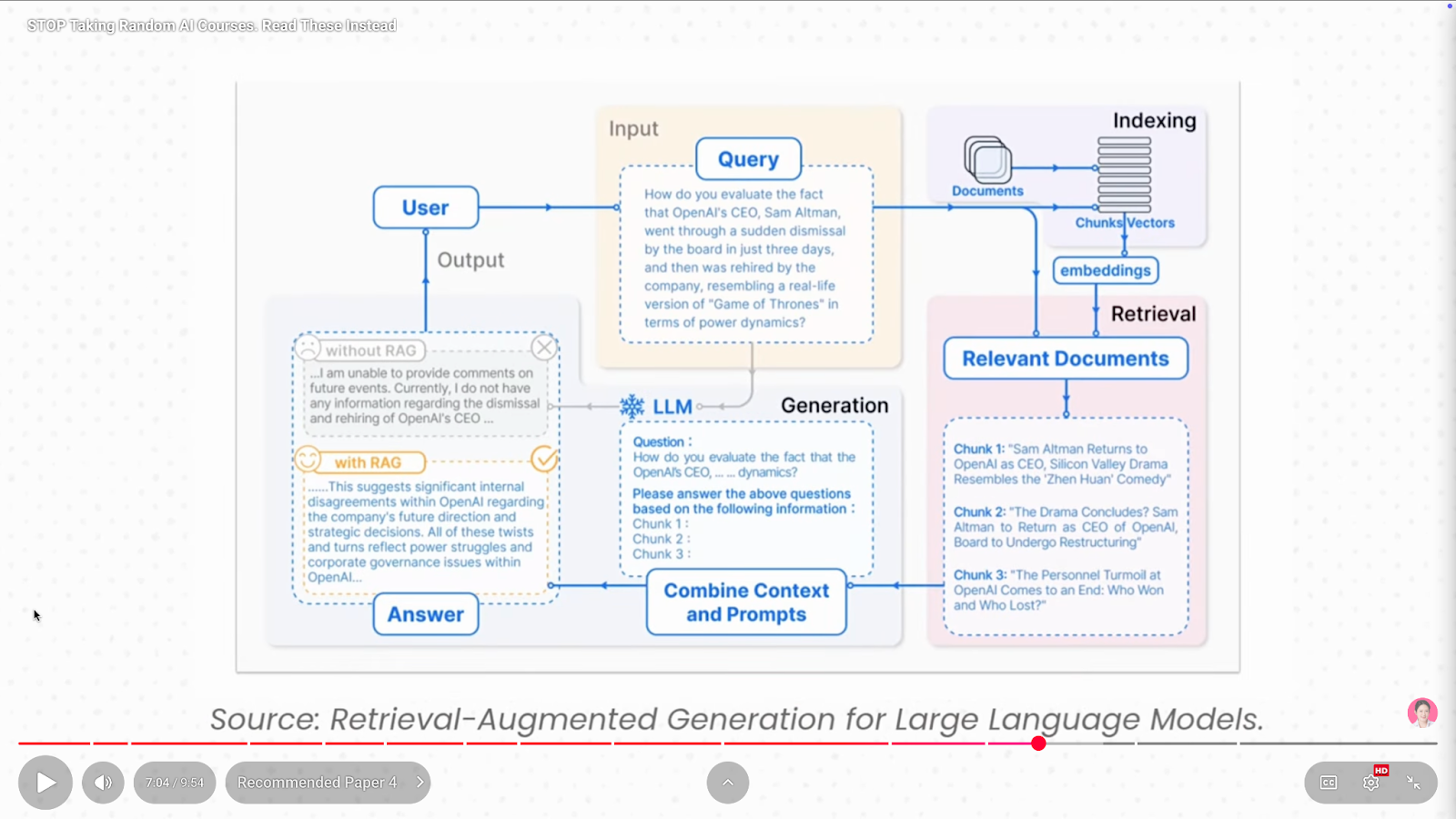
The survey describes three stages of RAG evolution:
RAG grounds the model in real facts instead of only relying on its training data.
This paper is about MCP, or Model Context Protocol, which lets AI models interact with tools, APIs, and software systems without custom integrations. Before MCP, every tool needed its own custom connector.
With MCP, agents can:
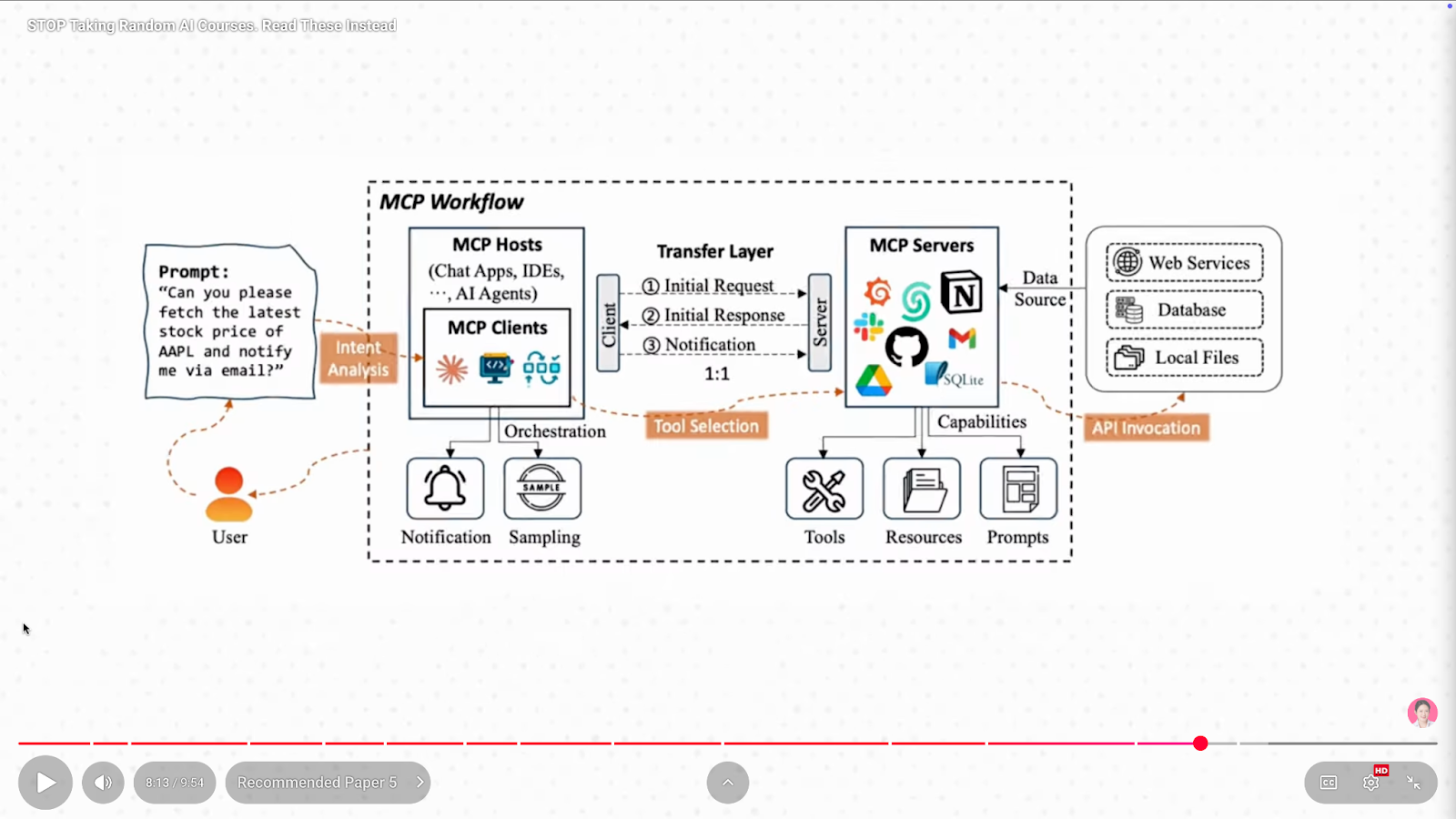
This paper matters for two reasons:
Together, they form the blueprint for how real AI systems will be built.
You don’t need to guess or search endlessly. Use these sources:
The easiest site to browse papers with matching code and leaderboards.
2. Distilled AI
Papers organized by year and topic, going back to 2010. Great for learning the evolution of an idea.
Fresh papers plus trending tweets. Set keyword alerts to avoid overwhelm.
4. arXiv Sanity
The main hub for AI research.
It can feel chaotic, so only use this once you know what you're looking for.
I also keep an updated list of links and free learning resources on my website.
Reading research papers is one of the fastest ways to understand what’s really happening in AI. You don’t need a PhD. You don’t need perfect math skills.
You just need:
AI is moving fast, but you can keep up and even stand out if you learn from the same sources the experts use.
If you want more step-by-step guidance on learning AI engineering, check the AI engineering roadmap video here.
If you have questions about learning AI, join the next free Q&A session. Sign up here!
Exaltitude newsletter is packed with advice for navigating your engineering career journey successfully. Sign up to stay tuned!



.png)


